Molecular Development - Rubella Genome: Difference between revisions
(Created page with " LOCUS RUBCG 9755 bp ss-RNA VRL 08-MAR-1996DEFINITION Rubella virus complete genome encoding nonstructural protein, capsid protein, gly...") |
mNo edit summary |
||
| (17 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
{{Header}} | |||
==Introduction== | |||
[[Image:Rubella_virus.jpg|thumb|alt=Rubella Virus EM|link=Abnormal Development - Rubella Virus|Rubella Virus, transmission electron micrograph (Image: CDC USA)]] | |||
The complete genomic sequence of Rubella is now known.<ref><pubmed>2353453</pubmed></ref> Rubella is a 9755 bp single stranded RNA positive-strand virus with no DNA stage (Togaviridae; Rubivirus) encoding non-structural protein, capsid protein, glycoproteins E1 and E2. | |||
[[Abnormal Development - Rubella Virus]] | |||
{{Viral Links}} | |||
==Lineage== | |||
Lineage: Viruses; ssRNA viruses; ssRNA positive-strand viruses, no DNA stage; Togaviridae; Rubivirus; Rubella virus | |||
==Sequence Information== | |||
===Sequence of the genome RNA of rubella virus: evidence for genetic rearrangement during toga virus evolution=== | |||
Virology. 1990 Jul;177(1):225-38. | |||
Dominguez G, Wang CY, Frey TK. | |||
Source | |||
Department of Biology, Georgia State University, Atlanta 30302-4010. | |||
Abstract | |||
The nucleotide sequence of the rubella virus (RUB) genomic RNA was determined. The RUB genomic RNA is 9757 nucleotides in length [excluding the poly(A) tail] and has a G/C content of 69.5%, the highest of any RNA virus sequenced to date. The RUB genomic RNA contains two long open reading frames (ORFs), a 5'-proximal ORF of 6656 nucleotides and a 3'-proximal ORF of 3189 nucleotides which encodes the structural proteins. Thus, the genomic organization of RUB is similar to that of alphaviruses, the other genus of the Togavirus family, and the 5'-proximal ORF of RUB therefore putatively codes for the nonstructural proteins. Sequences homologous to three regions of nucleotide sequence highly conserved among alphaviruses (a stem-and-loop structure at the 5' end of the genome, a 51-nucleotide conserved sequence near the 5' end of the genome, and a 20-nucleotide conserved sequence at the subgenomic RNA start site) were found in the RUB genomic RNA. Amino acid sequence comparisons between the nonstructural ORF of RUB and alphaviruses revealed only one short (122 amino acids) region of significant homology, indicating that these viruses are only distantly related. This region of homology is located at the NH2 terminus of nsP3 in the alphavirus genome. The RUB nonstructural protein ORF contains two global amino acid motifs conserved in a large number of positive-polarity RNA viruses, a motif indicative of helicase activity and a motif indicative of replicase activity. The order of the helicase motif and the nsP3 homology region in the RUB genome is reversed with respect to the alphavirus genome indicating that a genetic rearrangement has occurred during the evolution of these viruses. | |||
PMID 2353453 | |||
LOCUS RUBCG 9755 bp ss-RNA VRL 08-MAR-1996 | |||
DEFINITION Rubella virus complete genome encoding nonstructural protein, capsid protein, glycoproteins E1 and E2, complete cds. | |||
ACCESSION M15240 M18901 M32735 | |||
NID g333971 VERSION M15240.1 GI:333971 | |||
KEYWORDS C gene; capsid protein; glycoprotein; glycoprotein E1; glycoprotein E2; haemagglutinin; nonstructural protein. | |||
SOURCE ORGANISM Rubella virus | |||
Viruses; ssRNA positive-strand viruses, no DNA stage; Togaviridae; Rubivirus. | |||
==Protein Sequence== | |||
source 1..9755<br> /organism="Rubella virus"<br> /note="other clones: pRUB1010[1012, 1002, 1006, 1015,<br> 1001]"<br> /db_xref="taxon:11041"<br> /clone="pRUB1025"<br> CDS 39..6656<br> /note="nonstructural polyprotein precursor"<br> /codon_start=1<br> /protein_id="AAA88528.1"<br> /db_xref="PID:g333972"<br> /db_xref="GI:333972"<br> /translation="MEKLLDEVLAPGGPYNLTVGSWVRDHVRSIVEGAWEVRDVVTAA<br> QKRAIVAVIPRPVFTQMQVSDHPALHAISRYTRRHWIEWGPKEALHVLIDPSPGLLRE<br> VARVERRWVALCLHRTARKLATALAETASEAWHADYVCALRGAPSGPFYVHPEDVPHG<br> GRAVADRCLLYYTPMQMCELMRTIDATLLVAVDLWPVALAAHVGDDWDDLGIAWHLDH<br> DGGCPADCRGAGAGPTPGYTRPCTTRIYQVLPDTAHPGRLYRCGPRLWTRDCAVAELS<br> WEVAQHCGHQARVRAVRCTLPIRHVRSLQPSARVRLPDLVHLAEVGRWRWFSLPRPVF<br> QRMLSYCKTLSPDAYYSERVFKFKNALCHSITLAGNVLQEGWKGTCAEEDALCAYVAF<br> RAWQSNARLAGIMKGAKCAADSLSVAGWLDTIWDAIKRFLGSVPLAERMEEWEQDAAV<br> AAFDRGPLEDGGRHLDTVQPPKSPPRPEIAATWIVHAASEDRHCACAPRCDVPRERPS<br> APAGQPDDEALIPPWLFAERRALRCREWDFEALRARADTAAAPAPPAPRPARYPTVLY<br> RHPAHHGPWLTLDEPGEADAALVLCDPLGQPLRGPERHFAAGAHMCAQARGLQAFVRV<br> VPPPERPWADGGARAWAKFFRGCAWAQRLLGEPAVMHLPYTDGDVPQLIALALRTLAQ<br> QGAALALSVRDLPGGAAFDANAVTAAVRAGPRQSAAASPPPGDPPPPRRARRSQRHSD<br> ARGTPPPAPARDPPPPAPSPPAPPRAGDPVPPIPAGPADRARDAELEVACEPSGPPTS<br> TRADPDSDIVESYARAAGPVHLRVRDIMDPPPGCKVVVNAANEGLLAGSGVCGAIFAN<br> ATAALAANCRRLAPCPTGEAVATPGHGCGYTHIIHAVAPRRPRDPAALEEGEALLERA<br> YRSIVALAAARRWACVACPLLGAGVYGWSAAESLRAALAATRTEPVERVSLHICHPDR<br> ATLTHASVLVGAGLAARRVSPPPTEPLASCPAGDPGRPAQRSASPPATPLGDATAPEP<br> RGCQGCELCRYTRVTNDRAYVNLWLERDRGATSWAMRIPEVVVYGPEHLATHFPLNHY<br> SVLKPAEVRPPRGMCGSDMWRCRGWHGMPQVRCTPSNAHAALCRTGVPPRASTRGGEL<br> DPNTCWLRAAANVAQAARACGAYTSAGCPKCAYGRALSEARTHEDFAALSQRWSASHA<br> DASPDGTGDPLDPLMETVGCACSRVWVGSEHEAPPDHLLVSLHRAPNGPWGVVLEVRA<br> RPEGGNPTGHFVCAVGGGPRRVSDRPHLWLAVPLSRGGGTCAATDEGLAQAYYDDLEV<br> RRLGDDAMARAALASVQRPRKGPYNIRVWNMAAGAGKTTRILAAFTREDLYVCPTNAL<br> LHEIQAKLRARDIDIKNAATYERRLTKPLAAYRRIYIDEAFTLGGEYCAFVASQTTAE<br> VICVGDRDQCGPHYANNCRTPVPDRWPTERSRHTWRFPDCWAARLRAGLDYDIEGERT<br> GTFACNLWDGRQVDLHLAFSRETVRRLHEAGIRAYTVREAQGMSVGTACIHVGRDGTD<br> VALALTRDLAIVSLTRASDALYLHELEDGSLRAAGLSAFLDAGALAELKEVPAGIDRV<br> VAVEQAPPPLPPADGIPEAQDVPPFCPRTLEELVFGRAGHPHYADLNRVTEGEREVRY<br> MRISRHLLNKNHTEMPGTERVLSAVCAVRRYRAGEDGSTLRTAVARQHPRPFRQIPPP<br> RVTAGVAQEWRMTYLRERIDLTDVYTQMGVAARELTDRYARRYPEIFAGMCTAQSLSV<br> PAFLKATLKCVDAALGPRDTEDCHAAQGKAGLEIRAWAKEWVQVMSPHFRAIQKIIMR<br> ALRPQFLVAAGHTEPEVDAWWQAHYTTNAIEVDFTEFDMNQTLATRDVELEISAALLG<br> LPCAEDYRALRAGSYCTLRELGSTETGCERTSGEPATLLHNTTVAMCMAMRMVPKGVR<br> WAGIFQGDDMVIFLPEGARSAALKWTPAEVGLFGFHIPVKHVSTPTPSFCGHVGTAAG<br> LFHDVMHQAIKVLCRRFDPDVLEEQQVALLDRLRGVYAALPDTVAANAAYYDYSAERV<br> LAIVRELTAYAGARPRPPGHHRRARGDSDPLRARQSPRRRLTPLYVGPLILPTLTRSS<br> PTVVSPHLVGTQLLPFGRAPGCPNGFYYPHHHGGPPEGPRGTIPRPARGTRRRRLAVA<br> PAAAAATARLQHLRR"<br> mRNA 6428..9755<br> /note="subgenomic RNA"<br> mat_peptide 6505..7404<br> /note="capsid protein (C)"<br> CDS 6505..9696<br> /note="structural polyprotein precursor"<br> /codon_start=1<br> /protein_id="AAA88529.1"<br> /db_xref="PID:g333973"<br> /db_xref="GI:333973"<br> /translation="MASTTPITMEDLQKALEAQSRALRAELAAGASQSRRPRPPRQRD<br><br> SSTSGDDSGRDSGGPRRRRGNRGRGQRRDWSRAPPPPEERQETRSQTPAPKPSRAPPQ<br><br> QPQPPRMQTGRGGSAPRPELGPPTNPFQAAVARGLRPPLHDPDTEAPTEACVTSWLWS<br><br> EGEGAVFYRVDLHFTNLGTPPLDEDGRWDPALMYNPCGPEPPAHVVRAYNQPAGDVRG<br><br> VWGKGERTYAEQDFRVGGTRWHRLLRMPVRGLDGDSAPLPPHTTERIETRSARHPWRI<br><br> RFGAPQAFLAGLLLATVAVGTARAGLQPRADMAAPPTLPQPPCAHGQHYGHHHHQLPF<br><br> LGHDGHHGGTLRVGQHYRNASDVLPGHWLQGGWGCYNLSDWHQGTHVCHTKHMDFWCV<br><br> EHDRPPPATPTPLTTAANSTTAATPATAPAPCHAGLNDSCGGFLSGCGPMRLRHGADT<br><br> RCGRLICGLSTTAQYPPTRFGCAMRWGLPPWELVVLTARPEDGWTCRGVPAHPGARCP<br><br> ELVSPMGRATCSPASALWLATANALSLDHALAAFVLLVPWVLIFMVCRRACRRRGAAA<br><br> ALTAVVLQGYNPPAYGEEAFTYLCTAPGCATQAPVPVRLAGVRFESKIVDGGCFAPWD<br><br> LEATGACICEIPTDVSCEGLGAWVPAAPCARIWNGTQRACTFWAVNAYSSGGYAQLAS<br><br> YFNPGGSYYKQYHPTACEVEPAFGHSDAACWGFPTDTVMSVFALASYVQHPHKTVRVK<br><br> FHTETRTVWQLSVAGVSCNVTTEHPFCNTPHGQLEVQVPPDPGDLVEYIMNYTGNQQS<br><br> RWGLGSPNCHGPDWASPVCQRHSPDCSRLVGATPERPRLRLVDADDPLLRTAPGPGEV<br><br> WVTPVIGSQARKCGLHIRAGPYGHATVEMPEWIHAHTTSDPWHPPGPLGLKFKTVRPV<br><br> ALPRTLAPPRNVRVTGCYQCGTPALVEGLAPGGGNCHLTVNGEDLGAVPPGKFVTAAL<br><br> LNTPPPYQVSCGGESDRATARVIDPAAQSFTGVVYGTHTTAVSETRQTWAEWAAAHWW<br><br> QLTLGAICALPLAGLLACCAKCLYYLRGAIAPR" | |||
mat_peptide 7405..8250 ="glycoprotein E2" | |||
mat_peptide 8251..9693 ="glycoprotein E1" | |||
==Nucleotide Sequence== | |||
<br>BASE COUNT 1457 a 3781 c 3007 g 1510 t<br> | |||
ORIGIN | |||
1 atggaagcta tcggacctcg cttaggactc ccattcccat ggagaaactc ctagatgagg | |||
61 ttcttgcccc cggtgggcct tataacttaa ccgtcggcag ttgggtaaga gaccacgtcc | |||
121 gatcaattgt cgagggcgcg tgggaagtgc gcgatgttgt taccgctgcc caaaagcggg | |||
181 ccatcgtagc cgtgataccc agacctgtgt tcacgcagat gcaggtcagt gatcacccag | |||
241 cactccacgc aatttcgcgg tatacccgcc gccattggat cgagtggggc cctaaagaag | |||
301 ccctacacgt cctcatcgac ccaagcccgg gcctgctccg cgaggtcgct cgcgttgagc | |||
361 gccgctgggt cgcactgtgc ctccacagga cggcacgcaa actcgccacc gccctggccg | |||
421 agacggccag cgaggcgtgg cacgctgact acgtgtgcgc gctgcgtggc gcaccgagcg | |||
481 gccccttcta cgtccaccct gaggacgtcc cgcacggcgg tcgcgccgtg gcggacagat | |||
541 gcttgctcta ctacacaccc atgcagatgt gcgagctgat gcgtaccatt gacgccaccc | |||
601 tgctcgtggc ggttgacttg tggccggtcg cccttgcggc ccacgtcggc gacgactggg | |||
661 acgacctggg cattgcctgg catctcgacc atgacggcgg ttgccccgcc gattgccgcg | |||
721 gagccggcgc tgggcccacg cccggctaca cccgcccctg caccacacgc atctaccaag | |||
781 tcctgccgga caccgcccac cccgggcgcc tctaccggtg cgggccccgc ctgtggacgc | |||
841 gcgattgcgc cgtggccgaa ctctcatggg aggttgccca acactgcggg caccaggcgc | |||
901 gcgtgcgcgc cgtgcgatgc accctcccta tccgccacgt gcgcagcctc caacccagcg | |||
961 cgcgggtccg actcccggac ctcgtccatc tcgccgaggt gggccggtgg cggtggttca | |||
1021 gcctcccccg ccccgtgttc cagcgcatgc tgtcctactg caagaccctg agccccgacg | |||
1081 cgtactacag cgagcgcgtg ttcaagttca agaacgccct gtgccacagc atcacgctcg | |||
1141 cgggcaatgt gctgcaagag gggtggaagg gcacgtgcgc cgaggaagac gcgctgtgcg | |||
1201 catacgtagc cttccgcgcg tggcagtcta acgccaggtt ggcggggatt atgaaaggcg | |||
1261 cgaagtgcgc cgccgactct ttgagcgtgg ccggctggct ggacaccatt tgggacgcca | |||
1321 ttaagcggtt cctcggtagc gtgcccctcg ccgagcgcat ggaggagtgg gaacaggacg | |||
1381 ccgcggtcgc cgccttcgac cgcggccccc tcgaggacgg cgggcgccac ttggacaccg | |||
1441 tgcaaccccc aaaatcgccg ccccgccctg agatcgccgc gacctggatc gtccacgcag | |||
1501 ccagcgaaga ccgccattgc gcgtgcgctc cccgctgcga cgtcccgcgc gaacgtcctt | |||
1561 ccgcgcccgc cggccagccg gatgacgagg cgctcatccc gccgtggctg ttcgccgagc | |||
1621 gccgtgccct ccgctgccgc gagtgggatt tcgaggctct ccgcgcgcgc gccgatacgg | |||
1681 cggccgcgcc cgccccgccg gctccacgcc ccgcgcggta ccccaccgtg ctctaccgcc | |||
1741 accccgccca ccacggcccg tggctcaccc ttgacgagcc gggcgaggct gacgcggccc | |||
1801 tggtcttatg cgacccactt ggccagccgc tccggggccc tgaacgccac ttcgccgccg | |||
1861 gcgcgcatat gtgcgcgcag gcgcgggggc tccaggcttt tgtccgtgtc gtgcctccac | |||
1921 ccgagcgccc ctgggccgac gggggcgcca gagcgtgggc gaagttcttc cgcggctgcg | |||
1981 cctgggcgca gcgcttgctc ggcgagccag cagttatgca cctcccatac accgatggcg | |||
2041 acgtgccaca gctgatcgca ctggctttgc gcacgctggc ccaacagggg gccgccttgg | |||
2101 cactctcggt gcgtgacctg cccgggggtg cagcgttcga cgcaaacgcg gtcaccgccg | |||
2161 ccgtgcgcgc tggcccccgc cagtccgcgg ccgcgtcacc gccacccggc gaccccccgc | |||
2221 cgccgcgccg cgcacggcga tcgcaacggc actcggacgc tcgcggcact ccgccccccg | |||
2281 cgcctgcgcg cgacccgccg ccgcccgccc ccagcccgcc cgcgccaccc cgcgctggtg | |||
2341 acccggtccc tcccattccc gcggggccgg cggatcgcgc gcgtgacgcc gagctggagg | |||
2401 tcgcctgcga gccgagcggc ccccccacgt caaccagggc agacccagac agcgacatcg | |||
2461 ttgaaagtta cgcccgcgcc gccggacccg tgcacctccg agtccgcgac atcatggacc | |||
2521 caccgcccgg ctgcaaggtc gtggtcaacg ccgccaacga ggggctactg gccggctctg | |||
2581 gcgtgtgcgg tgccatcttt gccaacgcca cggcggccct cgctgcaaac tgccggcgcc | |||
2641 tcgccccatg ccccaccggc gaggcagtgg cgacacccgg ccacggctgc gggtacaccc | |||
2701 acatcatcca cgccgtcgcg ccgcggcgtc ctcgggaccc cgccgccctc gaggagggcg | |||
2761 aagcgctgct cgagcgcgcc taccgcagca tcgtcgcgct agccgccgcg cgtcggtggg | |||
2821 cgtgtgtcgc gtgccccctc ctcggcgctg gcgtctacgg ctggtctgct gcggagtccc | |||
2881 tccgagccgc gctcgcggct acgcgcaccg agcccgtcga gcgcgtgagc ctgcacatct | |||
2941 gccaccccga ccgcgccacg ctgacgcacg cctccgtgct cgtcggcgcg gggctcgctg | |||
3001 ccaggcgcgt cagtcctcct ccgaccgagc ccctcgcatc ttgccccgcc ggtgacccgg | |||
3061 gccgaccggc tcagcgcagc gcgtcgcccc cagcgacccc ccttggggat gccaccgcgc | |||
3121 ccgagccccg cggatgccag gggtgcgaac tctgccggta cacgcgcgtc accaatgacc | |||
3181 gcgcctatgt caacctgtgg ctcgagcgcg accgcggcgc caccagctgg gccatgcgca | |||
3241 ttcccgaggt ggttgtctac gggccggagc acctcgccac gcattttcca ttaaaccact | |||
3301 acagtgtgct caagcccgcg gaggtcaggc ccccgcgagg catgtgcggg agtgacatgt | |||
3361 ggcgctgccg cggctggcat ggcatgccgc aggtgcggtg caccccctcc aacgctcacg | |||
3421 ccgccctgtg ccgcacaggc gtgccccctc gggcgagcac gcgaggcggc gagctagacc | |||
3481 caaacacctg ctggctccgc gccgccgcca acgttgcgca ggctgcgcgc gcctgcggcg | |||
3541 cctacacgag tgccgggtgc cccaagtgcg cctacggccg cgccctgagc gaagcccgca | |||
3601 ctcatgagga cttcgccgcg ctgagccagc ggtggagcgc gagccacgcc gatgcctccc | |||
3661 ctgacggcac cggagatccc ctcgaccccc tgatggagac cgtgggatgc gcctgttcgc | |||
3721 gcgtgtgggt cggctccgag catgaggccc cgcccgacca cctcctggtg tcccttcacc | |||
3781 gtgccccaaa tggtccgtgg ggcgtagtgc tcgaggtgcg tgcgcgcccc gaggggggca | |||
3841 accccaccgg ccacttcgtc tgcgcggtcg gcggcggccc acgccgcgtc tcggaccgcc | |||
3901 cccacctctg gcttgcggtc cccctgtctc ggggcggtgg cacctgtgcc gcgaccgacg | |||
3961 aggggctggc ccaggcgtac tacgacgacc tcgaggtgcg ccgcctcggg gatgacgcca | |||
4021 tggcccgggc ggccctcgca tcagtccaac gccctcgcaa aggcccttac aatatcaggg | |||
4081 tatggaacat ggccgcaggc gctggcaaga ctacccgcat cctcgctgcc ttcacgcgcg | |||
4141 aagaccttta cgtctgcccc accaatgcgc tcctgcacga gatccaggcc aaactccgcg | |||
4201 cgcgcgatat cgacatcaag aacgccgcca cctacgagcg ccggctgacg aaaccgctcg | |||
4261 ccgcctaccg ccgcatctac atcgatgagg cgttcactct cggcggcgag tactgcgcgt | |||
4321 tcgttgccag ccaaaccacc gcggaggtga tctgcgtcgg tgatcgggac cagtgcggcc | |||
4381 cacactacgc caataactgc cgcacccccg tccctgaccg ctggcctacc gagcgctcgc | |||
4441 gccacacttg gcgcttcccc gactgctggg cggcccgcct gcgcgcgggg ctcgattatg | |||
4501 acatcgaggg cgagcgcacc ggcaccttcg cctgcaacct ttgggacggc cgccaggtcg | |||
4561 accttcacct cgccttctcg cgcgaaaccg tgcgccgcct tcacgaggct ggcatacgcg | |||
4621 catacaccgt gcgcgaggcc cagggtatga gcgtcggcac cgcctgcatc catgtaggca | |||
4681 gagacggcac ggacgttgcc ctggcgctga cacgcgacct cgccatcgtc agcctgaccc | |||
4741 gggcctccga cgcactctac ctccacgagc tcgaggacgg ctcactgcgc gctgcggggc | |||
4801 tcagcgcgtt cctcgacgcc ggggcactgg cggagctcaa ggaggttccc gctggcattg | |||
4861 accgcgttgt cgccgtcgag caggcaccac caccgttgcc gcccgccgac ggcatccccg | |||
4921 aggcccaaga cgtgccgccc ttctgccccc gcactctgga ggagctcgtc ttcggccgtg | |||
4981 ccggccaccc ccattacgcg gacctcaacc gcgtgactga gggcgaacga gaagtgcggt | |||
5041 acatgcgcat ctcgcgtcac ctgctcaaca agaatcacac cgagatgccc ggaacggaac | |||
5101 gcgttctcag tgccgtttgc gccgtgcggc gctaccgcgc gggcgaggat gggtcgaccc | |||
5161 tccgcactgc tgtggcccgc cagcacccgc gcccttttcg ccagatccca cccccgcgcg | |||
5221 tcactgctgg ggtcgcccag gagtggcgca tgacgtactt gcgggaacgg atcgacctca | |||
5281 ctgatgtcta cacgcagatg ggcgtggccg cgcgggagct caccgaccgc tacgcgcgcc | |||
5341 gctatcctga gatcttcgcc ggcatgtgta ccgcccagag cctgagcgtc cccgccttcc | |||
5401 tcaaagccac cttgaagtgc gtagacgccg ccctcggccc cagggacacc gaggactgcc | |||
5461 acgccgctca ggggaaagcc ggccttgaga tccgggcgtg ggccaaggag tgggttcagg | |||
5521 ttatgtcccc gcatttccgc gcgatccaga agatcatcat gcgcgccttg cgcccgcaat | |||
5581 tccttgtggc cgctggccat acggagcccg aggtcgatgc gtggtggcag gcccattaca | |||
5641 ccaccaacgc catcgaggtc gacttcactg agttcgacat gaaccagacc ctcgctactc | |||
5701 gggacgtcga gctcgagatt agcgccgctc tcttgggcct cccttgcgcc gaagactacc | |||
5761 gcgcgctccg cgccggcagc tactgcaccc tgcgcgaact gggctccact gagaccggct | |||
5821 gcgagcgcac aagcggcgag cccgccacgc tgctgcacaa caccaccgtg gccatgtgca | |||
5881 tggccatgcg catggtcccc aaaggcgtgc gctgggccgg gattttccag ggtgacgata | |||
5941 tggtcatctt cctccccgag ggcgcgcgca gcgcggcact caagtggacc cccgccgagg | |||
6001 tgggcttgtt tggcttccac atcccggtga agcacgtgag cacccctacc cccagcttct | |||
6061 gcgggcacgt cggcaccgcg gccggcctct tccatgatgt catgcaccag gcgatcaagg | |||
6121 tgctttgccg ccgtttcgac ccagacgtgc ttgaagaaca gcaggtggcc ctcctcgacc | |||
6181 gcctccgggg ggtctacgcg gctctgcctg acaccgttgc cgccaatgct gcgtactacg | |||
6241 actacagcgc ggagcgcgtc ctcgctatcg tgcgcgaact taccgcgtac gcgggggcgc | |||
6301 ggcctcgacc acccggccac catcggcgcg ctcgaggaga ttcagacccc ctacgcgcgc | |||
6361 gccaatctcc acgacgccga ctaacgcccc tgtacgtggg gcctttaatc ttacctactc | |||
6421 taaccaggtc atcacccacc gttgtttcgc cgcatctggt gggtacccaa cttttgccat | |||
6481 tcgggagagc cccagggtgc ccgaatggct tctactaccc ccatcaccat ggaggacctc | |||
6541 cagaaggccc tcgaggcaca atcccgcgcc ctgcgcgcgg aactcgccgc cggcgcctcg | |||
6601 cagtcgcgcc ggccgcggcc gccgcgacag cgcgactcca gcacctccgg agatgactcc | |||
6661 ggccgtgact ccggagggcc ccgccgccgc cgcggcaacc ggggccgtgg ccagcgcagg | |||
6721 gactggtcca gggccccgcc ccccccggag gagcggcaag aaactcgctc ccagactccg | |||
6781 gccccgaagc catcgcgggc gccgccacaa cagcctcaac ccccgcgcat gcaaaccggg | |||
6841 cgtgggggct ctgccccgcg ccccgagctg gggccaccga ccaacccgtt ccaagcagcc | |||
6901 gtggcgcgtg gcctgcgccc gcctctccac gaccctgaca ccgaggcacc caccgaggcc | |||
6961 tgcgtgacct cgtggctttg gagcgagggc gaaggcgcgg tcttttaccg cgtcgacctg | |||
7021 catttcacca acctgggcac ccccccactc gacgaggacg gccgctggga ccctgcgctc | |||
7081 atgtacaacc cttgcgggcc cgagccgccc gctcacgtcg tccgcgcgta caatcaacct | |||
7141 gccggcgacg tcaggggcgt ttggggtaaa ggcgagcgca cctacgccga gcaggacttc | |||
7201 cgcgtcggcg gcacgcgctg gcaccgactg ctgcgcatgc cagtgcgcgg cctcgacggc | |||
7261 gacagcgccc cgcttccccc ccacaccacc gagcgcattg agacccgctc ggcgcgccat | |||
7321 ccttggcgca tccgcttcgg tgccccccag gccttccttg ccgggctctt gctcgccacg | |||
7381 gtcgccgttg gcaccgcgcg cgccgggctc cagccccgcg ctgatatggc ggcacctcct | |||
7441 acgctgccgc agcccccctg tgcgcacggg cagcattacg gccaccacca ccatcagctg | |||
7501 ccgttcctcg ggcacgacgg ccatcatggc ggcaccttgc gcgtcggcca gcattaccga | |||
7561 aacgccagcg acgtgctgcc cggccactgg ctccaaggcg gctggggttg ctacaacctg | |||
7621 agcgactggc accagggcac tcatgtctgt cataccaagc acatggactt ctggtgtgtg | |||
7681 gagcacgacc gaccgccgcc cgcgaccccg acgcctctca ccaccgcggc gaactccacg | |||
7741 accgccgcca cccccgccac tgcgccggcc ccctgccacg ccggcctcaa tgacagctgc | |||
7801 ggcggcttct tgtctgggtg cgggccgatg cgcctgcgcc acggcgctga cacccggtgc | |||
7861 ggtcggttga tctgcgggct gtccaccacc gcccagtacc cgcctacccg gtttggctgc | |||
7921 gctatgcggt ggggccttcc cccctgggaa ctggtcgtcc ttaccgcccg ccccgaagac | |||
7981 ggctggactt gccgcggcgt gcccgcccat ccaggcgccc gctgccccga actggtgagc | |||
8041 cccatgggac gcgcgacttg ctccccagcc tcggccctct ggctcgccac agcgaacgcg | |||
8101 ctgtctcttg atcacgccct cgcggccttc gtcctgctgg tcccgtgggt cctgatattt | |||
8161 atggtgtgcc gccgcgcctg tcgccgccgc ggcgccgccg ccgccctcac cgcggtcgtc | |||
8221 ctgcaggggt acaacccccc cgcctatggc gaggaggctt tcacctacct ctgcactgca | |||
8281 ccggggtgcg ccactcaagc acctgtcccc gtgcgcctcg ctggcgtccg ttttgagtcc | |||
8341 aagattgtgg acggcggctg ctttgcccca tgggacctcg aggccactgg agcctgcatt | |||
8401 tgcgagatcc ccactgatgt ctcgtgcgag ggcttggggg cctgggtacc cgcagcccct | |||
8461 tgcgcgcgca tctggaatgg cacacagcgc gcgtgcacct tctgggctgt caacgcctac | |||
8521 tcctctggcg ggtacgcgca gctggcctct tacttcaacc ctggcggcag ctactacaag | |||
8581 cagtaccacc ctaccgcgtg cgaggttgaa cctgccttcg gacacagcga cgcggcctgc | |||
8641 tggggcttcc ccaccgacac cgtgatgagc gtgttcgccc ttgctagcta cgtccagcac | |||
8701 cctcacaaga ccgtccgggt caagttccat acagagacca ggaccgtctg gcaactctcc | |||
8761 gttgccggcg tgtcgtgcaa cgtcaccact gaacacccgt tctgcaacac gccgcacgga | |||
8821 caactcgagg tccaggtccc gcccgacccc ggggacctgg ttgagtacat tatgaattac | |||
8881 accggcaatc agcagtcccg gtggggcctc gggagcccga attgccacgg ccccgattgg | |||
8941 gcctccccgg tttgccaacg ccattcccct gactgctcgc ggcttgtggg ggccacgcca | |||
9001 gagcgccccc ggctgcgcct ggtcgacgcc gacgaccccc tgctgcgcac tgcccctgga | |||
9061 cccggcgagg tgtgggtcac gcctgtcata ggctctcagg cgcgcaagtg cggactccac | |||
9121 atacgcgctg gaccgtacgg ccatgctacc gtcgaaatgc ccgagtggat ccacgcccac | |||
9181 accaccagcg acccctggca tccaccgggc cccttggggc tgaagttcaa gacagttcgc | |||
9241 ccggtggccc tgccacgcac gttagcgcca ccccgcaatg tgcgtgtgac cgggtgctac | |||
9301 cagtgcggta cccccgcgct ggtggaaggc cttgcccccg ggggaggcaa ttgccatctc | |||
9361 accgtcaatg gcgaggacct cggcgccgtc ccccctggga agttcgtcac cgccgccctc | |||
9421 ctcaacaccc ccccgcccta ccaagtcagc tgcgggggcg agagcgatcg cgcgaccgcg | |||
9481 cgggtcatcg accccgccgc gcaatcgttt accggcgtgg tgtatggcac acacaccact | |||
9541 gctgtgtcgg agacccggca gacctgggcg gagtgggctg ctgcccattg gtggcagctc | |||
9601 actctgggcg ccatttgcgc cctcccactc gctggcttac tcgcttgctg tgccaaatgc | |||
9661 ttgtactact tgcgcggcgc tatagcgcct cgctagtggg cccccgcgcg aaacccgcac | |||
9721 taggccacta gatccccgca cctgttgctg tatag | |||
==References== | |||
<references/> | |||
==External Links== | |||
{{External Links}} | |||
* NCBI [http://www.ncbi.nlm.nih.gov/nuccore/NC_001545?report=graph&from=1&to=9762 Rubella virus, complete genome] | |||
{{Glossary}} | |||
{{Footer}} | |||
[[Category:Rubella]][[Category:Molecular]] | |||
Latest revision as of 15:01, 29 September 2015
| Embryology - 19 Apr 2024 |
|---|
| Google Translate - select your language from the list shown below (this will open a new external page) |
|
العربية | català | 中文 | 中國傳統的 | français | Deutsche | עִברִית | हिंदी | bahasa Indonesia | italiano | 日本語 | 한국어 | မြန်မာ | Pilipino | Polskie | português | ਪੰਜਾਬੀ ਦੇ | Română | русский | Español | Swahili | Svensk | ไทย | Türkçe | اردو | ייִדיש | Tiếng Việt These external translations are automated and may not be accurate. (More? About Translations) |
Introduction
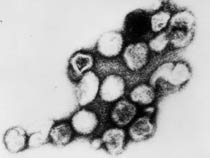
{kind=link}
The complete genomic sequence of Rubella is now known.[1] Rubella is a 9755 bp single stranded RNA positive-strand virus with no DNA stage (Togaviridae; Rubivirus) encoding non-structural protein, capsid protein, glycoproteins E1 and E2.
Abnormal Development - Rubella Virus
Lineage
Lineage: Viruses; ssRNA viruses; ssRNA positive-strand viruses, no DNA stage; Togaviridae; Rubivirus; Rubella virus
Sequence Information
Sequence of the genome RNA of rubella virus: evidence for genetic rearrangement during toga virus evolution
Virology. 1990 Jul;177(1):225-38.
Dominguez G, Wang CY, Frey TK. Source Department of Biology, Georgia State University, Atlanta 30302-4010.
Abstract
The nucleotide sequence of the rubella virus (RUB) genomic RNA was determined. The RUB genomic RNA is 9757 nucleotides in length [excluding the poly(A) tail] and has a G/C content of 69.5%, the highest of any RNA virus sequenced to date. The RUB genomic RNA contains two long open reading frames (ORFs), a 5'-proximal ORF of 6656 nucleotides and a 3'-proximal ORF of 3189 nucleotides which encodes the structural proteins. Thus, the genomic organization of RUB is similar to that of alphaviruses, the other genus of the Togavirus family, and the 5'-proximal ORF of RUB therefore putatively codes for the nonstructural proteins. Sequences homologous to three regions of nucleotide sequence highly conserved among alphaviruses (a stem-and-loop structure at the 5' end of the genome, a 51-nucleotide conserved sequence near the 5' end of the genome, and a 20-nucleotide conserved sequence at the subgenomic RNA start site) were found in the RUB genomic RNA. Amino acid sequence comparisons between the nonstructural ORF of RUB and alphaviruses revealed only one short (122 amino acids) region of significant homology, indicating that these viruses are only distantly related. This region of homology is located at the NH2 terminus of nsP3 in the alphavirus genome. The RUB nonstructural protein ORF contains two global amino acid motifs conserved in a large number of positive-polarity RNA viruses, a motif indicative of helicase activity and a motif indicative of replicase activity. The order of the helicase motif and the nsP3 homology region in the RUB genome is reversed with respect to the alphavirus genome indicating that a genetic rearrangement has occurred during the evolution of these viruses.
PMID 2353453
LOCUS RUBCG 9755 bp ss-RNA VRL 08-MAR-1996
DEFINITION Rubella virus complete genome encoding nonstructural protein, capsid protein, glycoproteins E1 and E2, complete cds.
ACCESSION M15240 M18901 M32735
NID g333971 VERSION M15240.1 GI:333971
KEYWORDS C gene; capsid protein; glycoprotein; glycoprotein E1; glycoprotein E2; haemagglutinin; nonstructural protein.
SOURCE ORGANISM Rubella virus
Viruses; ssRNA positive-strand viruses, no DNA stage; Togaviridae; Rubivirus.
Protein Sequence
source 1..9755
/organism="Rubella virus"
/note="other clones: pRUB1010[1012, 1002, 1006, 1015,
1001]"
/db_xref="taxon:11041"
/clone="pRUB1025"
CDS 39..6656
/note="nonstructural polyprotein precursor"
/codon_start=1
/protein_id="AAA88528.1"
/db_xref="PID:g333972"
/db_xref="GI:333972"
/translation="MEKLLDEVLAPGGPYNLTVGSWVRDHVRSIVEGAWEVRDVVTAA
QKRAIVAVIPRPVFTQMQVSDHPALHAISRYTRRHWIEWGPKEALHVLIDPSPGLLRE
VARVERRWVALCLHRTARKLATALAETASEAWHADYVCALRGAPSGPFYVHPEDVPHG
GRAVADRCLLYYTPMQMCELMRTIDATLLVAVDLWPVALAAHVGDDWDDLGIAWHLDH
DGGCPADCRGAGAGPTPGYTRPCTTRIYQVLPDTAHPGRLYRCGPRLWTRDCAVAELS
WEVAQHCGHQARVRAVRCTLPIRHVRSLQPSARVRLPDLVHLAEVGRWRWFSLPRPVF
QRMLSYCKTLSPDAYYSERVFKFKNALCHSITLAGNVLQEGWKGTCAEEDALCAYVAF
RAWQSNARLAGIMKGAKCAADSLSVAGWLDTIWDAIKRFLGSVPLAERMEEWEQDAAV
AAFDRGPLEDGGRHLDTVQPPKSPPRPEIAATWIVHAASEDRHCACAPRCDVPRERPS
APAGQPDDEALIPPWLFAERRALRCREWDFEALRARADTAAAPAPPAPRPARYPTVLY
RHPAHHGPWLTLDEPGEADAALVLCDPLGQPLRGPERHFAAGAHMCAQARGLQAFVRV
VPPPERPWADGGARAWAKFFRGCAWAQRLLGEPAVMHLPYTDGDVPQLIALALRTLAQ
QGAALALSVRDLPGGAAFDANAVTAAVRAGPRQSAAASPPPGDPPPPRRARRSQRHSD
ARGTPPPAPARDPPPPAPSPPAPPRAGDPVPPIPAGPADRARDAELEVACEPSGPPTS
TRADPDSDIVESYARAAGPVHLRVRDIMDPPPGCKVVVNAANEGLLAGSGVCGAIFAN
ATAALAANCRRLAPCPTGEAVATPGHGCGYTHIIHAVAPRRPRDPAALEEGEALLERA
YRSIVALAAARRWACVACPLLGAGVYGWSAAESLRAALAATRTEPVERVSLHICHPDR
ATLTHASVLVGAGLAARRVSPPPTEPLASCPAGDPGRPAQRSASPPATPLGDATAPEP
RGCQGCELCRYTRVTNDRAYVNLWLERDRGATSWAMRIPEVVVYGPEHLATHFPLNHY
SVLKPAEVRPPRGMCGSDMWRCRGWHGMPQVRCTPSNAHAALCRTGVPPRASTRGGEL
DPNTCWLRAAANVAQAARACGAYTSAGCPKCAYGRALSEARTHEDFAALSQRWSASHA
DASPDGTGDPLDPLMETVGCACSRVWVGSEHEAPPDHLLVSLHRAPNGPWGVVLEVRA
RPEGGNPTGHFVCAVGGGPRRVSDRPHLWLAVPLSRGGGTCAATDEGLAQAYYDDLEV
RRLGDDAMARAALASVQRPRKGPYNIRVWNMAAGAGKTTRILAAFTREDLYVCPTNAL
LHEIQAKLRARDIDIKNAATYERRLTKPLAAYRRIYIDEAFTLGGEYCAFVASQTTAE
VICVGDRDQCGPHYANNCRTPVPDRWPTERSRHTWRFPDCWAARLRAGLDYDIEGERT
GTFACNLWDGRQVDLHLAFSRETVRRLHEAGIRAYTVREAQGMSVGTACIHVGRDGTD
VALALTRDLAIVSLTRASDALYLHELEDGSLRAAGLSAFLDAGALAELKEVPAGIDRV
VAVEQAPPPLPPADGIPEAQDVPPFCPRTLEELVFGRAGHPHYADLNRVTEGEREVRY
MRISRHLLNKNHTEMPGTERVLSAVCAVRRYRAGEDGSTLRTAVARQHPRPFRQIPPP
RVTAGVAQEWRMTYLRERIDLTDVYTQMGVAARELTDRYARRYPEIFAGMCTAQSLSV
PAFLKATLKCVDAALGPRDTEDCHAAQGKAGLEIRAWAKEWVQVMSPHFRAIQKIIMR
ALRPQFLVAAGHTEPEVDAWWQAHYTTNAIEVDFTEFDMNQTLATRDVELEISAALLG
LPCAEDYRALRAGSYCTLRELGSTETGCERTSGEPATLLHNTTVAMCMAMRMVPKGVR
WAGIFQGDDMVIFLPEGARSAALKWTPAEVGLFGFHIPVKHVSTPTPSFCGHVGTAAG
LFHDVMHQAIKVLCRRFDPDVLEEQQVALLDRLRGVYAALPDTVAANAAYYDYSAERV
LAIVRELTAYAGARPRPPGHHRRARGDSDPLRARQSPRRRLTPLYVGPLILPTLTRSS
PTVVSPHLVGTQLLPFGRAPGCPNGFYYPHHHGGPPEGPRGTIPRPARGTRRRRLAVA
PAAAAATARLQHLRR"
mRNA 6428..9755
/note="subgenomic RNA"
mat_peptide 6505..7404
/note="capsid protein (C)"
CDS 6505..9696
/note="structural polyprotein precursor"
/codon_start=1
/protein_id="AAA88529.1"
/db_xref="PID:g333973"
/db_xref="GI:333973"
/translation="MASTTPITMEDLQKALEAQSRALRAELAAGASQSRRPRPPRQRD
SSTSGDDSGRDSGGPRRRRGNRGRGQRRDWSRAPPPPEERQETRSQTPAPKPSRAPPQ
QPQPPRMQTGRGGSAPRPELGPPTNPFQAAVARGLRPPLHDPDTEAPTEACVTSWLWS
EGEGAVFYRVDLHFTNLGTPPLDEDGRWDPALMYNPCGPEPPAHVVRAYNQPAGDVRG
VWGKGERTYAEQDFRVGGTRWHRLLRMPVRGLDGDSAPLPPHTTERIETRSARHPWRI
RFGAPQAFLAGLLLATVAVGTARAGLQPRADMAAPPTLPQPPCAHGQHYGHHHHQLPF
LGHDGHHGGTLRVGQHYRNASDVLPGHWLQGGWGCYNLSDWHQGTHVCHTKHMDFWCV
EHDRPPPATPTPLTTAANSTTAATPATAPAPCHAGLNDSCGGFLSGCGPMRLRHGADT
RCGRLICGLSTTAQYPPTRFGCAMRWGLPPWELVVLTARPEDGWTCRGVPAHPGARCP
ELVSPMGRATCSPASALWLATANALSLDHALAAFVLLVPWVLIFMVCRRACRRRGAAA
ALTAVVLQGYNPPAYGEEAFTYLCTAPGCATQAPVPVRLAGVRFESKIVDGGCFAPWD
LEATGACICEIPTDVSCEGLGAWVPAAPCARIWNGTQRACTFWAVNAYSSGGYAQLAS
YFNPGGSYYKQYHPTACEVEPAFGHSDAACWGFPTDTVMSVFALASYVQHPHKTVRVK
FHTETRTVWQLSVAGVSCNVTTEHPFCNTPHGQLEVQVPPDPGDLVEYIMNYTGNQQS
RWGLGSPNCHGPDWASPVCQRHSPDCSRLVGATPERPRLRLVDADDPLLRTAPGPGEV
WVTPVIGSQARKCGLHIRAGPYGHATVEMPEWIHAHTTSDPWHPPGPLGLKFKTVRPV
ALPRTLAPPRNVRVTGCYQCGTPALVEGLAPGGGNCHLTVNGEDLGAVPPGKFVTAAL
LNTPPPYQVSCGGESDRATARVIDPAAQSFTGVVYGTHTTAVSETRQTWAEWAAAHWW
QLTLGAICALPLAGLLACCAKCLYYLRGAIAPR"
mat_peptide 7405..8250 ="glycoprotein E2"
mat_peptide 8251..9693 ="glycoprotein E1"
Nucleotide Sequence
BASE COUNT 1457 a 3781 c 3007 g 1510 t
ORIGIN
1 atggaagcta tcggacctcg cttaggactc ccattcccat ggagaaactc ctagatgagg
61 ttcttgcccc cggtgggcct tataacttaa ccgtcggcag ttgggtaaga gaccacgtcc
121 gatcaattgt cgagggcgcg tgggaagtgc gcgatgttgt taccgctgcc caaaagcggg
181 ccatcgtagc cgtgataccc agacctgtgt tcacgcagat gcaggtcagt gatcacccag
241 cactccacgc aatttcgcgg tatacccgcc gccattggat cgagtggggc cctaaagaag
301 ccctacacgt cctcatcgac ccaagcccgg gcctgctccg cgaggtcgct cgcgttgagc
361 gccgctgggt cgcactgtgc ctccacagga cggcacgcaa actcgccacc gccctggccg
421 agacggccag cgaggcgtgg cacgctgact acgtgtgcgc gctgcgtggc gcaccgagcg
481 gccccttcta cgtccaccct gaggacgtcc cgcacggcgg tcgcgccgtg gcggacagat
541 gcttgctcta ctacacaccc atgcagatgt gcgagctgat gcgtaccatt gacgccaccc
601 tgctcgtggc ggttgacttg tggccggtcg cccttgcggc ccacgtcggc gacgactggg
661 acgacctggg cattgcctgg catctcgacc atgacggcgg ttgccccgcc gattgccgcg
721 gagccggcgc tgggcccacg cccggctaca cccgcccctg caccacacgc atctaccaag
781 tcctgccgga caccgcccac cccgggcgcc tctaccggtg cgggccccgc ctgtggacgc
841 gcgattgcgc cgtggccgaa ctctcatggg aggttgccca acactgcggg caccaggcgc
901 gcgtgcgcgc cgtgcgatgc accctcccta tccgccacgt gcgcagcctc caacccagcg
961 cgcgggtccg actcccggac ctcgtccatc tcgccgaggt gggccggtgg cggtggttca
1021 gcctcccccg ccccgtgttc cagcgcatgc tgtcctactg caagaccctg agccccgacg
1081 cgtactacag cgagcgcgtg ttcaagttca agaacgccct gtgccacagc atcacgctcg
1141 cgggcaatgt gctgcaagag gggtggaagg gcacgtgcgc cgaggaagac gcgctgtgcg
1201 catacgtagc cttccgcgcg tggcagtcta acgccaggtt ggcggggatt atgaaaggcg
1261 cgaagtgcgc cgccgactct ttgagcgtgg ccggctggct ggacaccatt tgggacgcca
1321 ttaagcggtt cctcggtagc gtgcccctcg ccgagcgcat ggaggagtgg gaacaggacg
1381 ccgcggtcgc cgccttcgac cgcggccccc tcgaggacgg cgggcgccac ttggacaccg
1441 tgcaaccccc aaaatcgccg ccccgccctg agatcgccgc gacctggatc gtccacgcag
1501 ccagcgaaga ccgccattgc gcgtgcgctc cccgctgcga cgtcccgcgc gaacgtcctt
1561 ccgcgcccgc cggccagccg gatgacgagg cgctcatccc gccgtggctg ttcgccgagc
1621 gccgtgccct ccgctgccgc gagtgggatt tcgaggctct ccgcgcgcgc gccgatacgg
1681 cggccgcgcc cgccccgccg gctccacgcc ccgcgcggta ccccaccgtg ctctaccgcc
1741 accccgccca ccacggcccg tggctcaccc ttgacgagcc gggcgaggct gacgcggccc
1801 tggtcttatg cgacccactt ggccagccgc tccggggccc tgaacgccac ttcgccgccg
1861 gcgcgcatat gtgcgcgcag gcgcgggggc tccaggcttt tgtccgtgtc gtgcctccac
1921 ccgagcgccc ctgggccgac gggggcgcca gagcgtgggc gaagttcttc cgcggctgcg
1981 cctgggcgca gcgcttgctc ggcgagccag cagttatgca cctcccatac accgatggcg
2041 acgtgccaca gctgatcgca ctggctttgc gcacgctggc ccaacagggg gccgccttgg
2101 cactctcggt gcgtgacctg cccgggggtg cagcgttcga cgcaaacgcg gtcaccgccg
2161 ccgtgcgcgc tggcccccgc cagtccgcgg ccgcgtcacc gccacccggc gaccccccgc
2221 cgccgcgccg cgcacggcga tcgcaacggc actcggacgc tcgcggcact ccgccccccg
2281 cgcctgcgcg cgacccgccg ccgcccgccc ccagcccgcc cgcgccaccc cgcgctggtg
2341 acccggtccc tcccattccc gcggggccgg cggatcgcgc gcgtgacgcc gagctggagg
2401 tcgcctgcga gccgagcggc ccccccacgt caaccagggc agacccagac agcgacatcg
2461 ttgaaagtta cgcccgcgcc gccggacccg tgcacctccg agtccgcgac atcatggacc
2521 caccgcccgg ctgcaaggtc gtggtcaacg ccgccaacga ggggctactg gccggctctg
2581 gcgtgtgcgg tgccatcttt gccaacgcca cggcggccct cgctgcaaac tgccggcgcc
2641 tcgccccatg ccccaccggc gaggcagtgg cgacacccgg ccacggctgc gggtacaccc
2701 acatcatcca cgccgtcgcg ccgcggcgtc ctcgggaccc cgccgccctc gaggagggcg
2761 aagcgctgct cgagcgcgcc taccgcagca tcgtcgcgct agccgccgcg cgtcggtggg
2821 cgtgtgtcgc gtgccccctc ctcggcgctg gcgtctacgg ctggtctgct gcggagtccc
2881 tccgagccgc gctcgcggct acgcgcaccg agcccgtcga gcgcgtgagc ctgcacatct
2941 gccaccccga ccgcgccacg ctgacgcacg cctccgtgct cgtcggcgcg gggctcgctg
3001 ccaggcgcgt cagtcctcct ccgaccgagc ccctcgcatc ttgccccgcc ggtgacccgg
3061 gccgaccggc tcagcgcagc gcgtcgcccc cagcgacccc ccttggggat gccaccgcgc
3121 ccgagccccg cggatgccag gggtgcgaac tctgccggta cacgcgcgtc accaatgacc
3181 gcgcctatgt caacctgtgg ctcgagcgcg accgcggcgc caccagctgg gccatgcgca
3241 ttcccgaggt ggttgtctac gggccggagc acctcgccac gcattttcca ttaaaccact
3301 acagtgtgct caagcccgcg gaggtcaggc ccccgcgagg catgtgcggg agtgacatgt
3361 ggcgctgccg cggctggcat ggcatgccgc aggtgcggtg caccccctcc aacgctcacg
3421 ccgccctgtg ccgcacaggc gtgccccctc gggcgagcac gcgaggcggc gagctagacc
3481 caaacacctg ctggctccgc gccgccgcca acgttgcgca ggctgcgcgc gcctgcggcg
3541 cctacacgag tgccgggtgc cccaagtgcg cctacggccg cgccctgagc gaagcccgca
3601 ctcatgagga cttcgccgcg ctgagccagc ggtggagcgc gagccacgcc gatgcctccc
3661 ctgacggcac cggagatccc ctcgaccccc tgatggagac cgtgggatgc gcctgttcgc
3721 gcgtgtgggt cggctccgag catgaggccc cgcccgacca cctcctggtg tcccttcacc
3781 gtgccccaaa tggtccgtgg ggcgtagtgc tcgaggtgcg tgcgcgcccc gaggggggca
3841 accccaccgg ccacttcgtc tgcgcggtcg gcggcggccc acgccgcgtc tcggaccgcc
3901 cccacctctg gcttgcggtc cccctgtctc ggggcggtgg cacctgtgcc gcgaccgacg
3961 aggggctggc ccaggcgtac tacgacgacc tcgaggtgcg ccgcctcggg gatgacgcca
4021 tggcccgggc ggccctcgca tcagtccaac gccctcgcaa aggcccttac aatatcaggg
4081 tatggaacat ggccgcaggc gctggcaaga ctacccgcat cctcgctgcc ttcacgcgcg
4141 aagaccttta cgtctgcccc accaatgcgc tcctgcacga gatccaggcc aaactccgcg
4201 cgcgcgatat cgacatcaag aacgccgcca cctacgagcg ccggctgacg aaaccgctcg
4261 ccgcctaccg ccgcatctac atcgatgagg cgttcactct cggcggcgag tactgcgcgt
4321 tcgttgccag ccaaaccacc gcggaggtga tctgcgtcgg tgatcgggac cagtgcggcc
4381 cacactacgc caataactgc cgcacccccg tccctgaccg ctggcctacc gagcgctcgc
4441 gccacacttg gcgcttcccc gactgctggg cggcccgcct gcgcgcgggg ctcgattatg
4501 acatcgaggg cgagcgcacc ggcaccttcg cctgcaacct ttgggacggc cgccaggtcg
4561 accttcacct cgccttctcg cgcgaaaccg tgcgccgcct tcacgaggct ggcatacgcg
4621 catacaccgt gcgcgaggcc cagggtatga gcgtcggcac cgcctgcatc catgtaggca
4681 gagacggcac ggacgttgcc ctggcgctga cacgcgacct cgccatcgtc agcctgaccc
4741 gggcctccga cgcactctac ctccacgagc tcgaggacgg ctcactgcgc gctgcggggc
4801 tcagcgcgtt cctcgacgcc ggggcactgg cggagctcaa ggaggttccc gctggcattg
4861 accgcgttgt cgccgtcgag caggcaccac caccgttgcc gcccgccgac ggcatccccg
4921 aggcccaaga cgtgccgccc ttctgccccc gcactctgga ggagctcgtc ttcggccgtg
4981 ccggccaccc ccattacgcg gacctcaacc gcgtgactga gggcgaacga gaagtgcggt
5041 acatgcgcat ctcgcgtcac ctgctcaaca agaatcacac cgagatgccc ggaacggaac
5101 gcgttctcag tgccgtttgc gccgtgcggc gctaccgcgc gggcgaggat gggtcgaccc
5161 tccgcactgc tgtggcccgc cagcacccgc gcccttttcg ccagatccca cccccgcgcg
5221 tcactgctgg ggtcgcccag gagtggcgca tgacgtactt gcgggaacgg atcgacctca
5281 ctgatgtcta cacgcagatg ggcgtggccg cgcgggagct caccgaccgc tacgcgcgcc
5341 gctatcctga gatcttcgcc ggcatgtgta ccgcccagag cctgagcgtc cccgccttcc
5401 tcaaagccac cttgaagtgc gtagacgccg ccctcggccc cagggacacc gaggactgcc
5461 acgccgctca ggggaaagcc ggccttgaga tccgggcgtg ggccaaggag tgggttcagg
5521 ttatgtcccc gcatttccgc gcgatccaga agatcatcat gcgcgccttg cgcccgcaat
5581 tccttgtggc cgctggccat acggagcccg aggtcgatgc gtggtggcag gcccattaca
5641 ccaccaacgc catcgaggtc gacttcactg agttcgacat gaaccagacc ctcgctactc
5701 gggacgtcga gctcgagatt agcgccgctc tcttgggcct cccttgcgcc gaagactacc
5761 gcgcgctccg cgccggcagc tactgcaccc tgcgcgaact gggctccact gagaccggct
5821 gcgagcgcac aagcggcgag cccgccacgc tgctgcacaa caccaccgtg gccatgtgca
5881 tggccatgcg catggtcccc aaaggcgtgc gctgggccgg gattttccag ggtgacgata
5941 tggtcatctt cctccccgag ggcgcgcgca gcgcggcact caagtggacc cccgccgagg
6001 tgggcttgtt tggcttccac atcccggtga agcacgtgag cacccctacc cccagcttct
6061 gcgggcacgt cggcaccgcg gccggcctct tccatgatgt catgcaccag gcgatcaagg
6121 tgctttgccg ccgtttcgac ccagacgtgc ttgaagaaca gcaggtggcc ctcctcgacc
6181 gcctccgggg ggtctacgcg gctctgcctg acaccgttgc cgccaatgct gcgtactacg
6241 actacagcgc ggagcgcgtc ctcgctatcg tgcgcgaact taccgcgtac gcgggggcgc
6301 ggcctcgacc acccggccac catcggcgcg ctcgaggaga ttcagacccc ctacgcgcgc
6361 gccaatctcc acgacgccga ctaacgcccc tgtacgtggg gcctttaatc ttacctactc
6421 taaccaggtc atcacccacc gttgtttcgc cgcatctggt gggtacccaa cttttgccat
6481 tcgggagagc cccagggtgc ccgaatggct tctactaccc ccatcaccat ggaggacctc
6541 cagaaggccc tcgaggcaca atcccgcgcc ctgcgcgcgg aactcgccgc cggcgcctcg
6601 cagtcgcgcc ggccgcggcc gccgcgacag cgcgactcca gcacctccgg agatgactcc
6661 ggccgtgact ccggagggcc ccgccgccgc cgcggcaacc ggggccgtgg ccagcgcagg
6721 gactggtcca gggccccgcc ccccccggag gagcggcaag aaactcgctc ccagactccg
6781 gccccgaagc catcgcgggc gccgccacaa cagcctcaac ccccgcgcat gcaaaccggg
6841 cgtgggggct ctgccccgcg ccccgagctg gggccaccga ccaacccgtt ccaagcagcc
6901 gtggcgcgtg gcctgcgccc gcctctccac gaccctgaca ccgaggcacc caccgaggcc
6961 tgcgtgacct cgtggctttg gagcgagggc gaaggcgcgg tcttttaccg cgtcgacctg
7021 catttcacca acctgggcac ccccccactc gacgaggacg gccgctggga ccctgcgctc
7081 atgtacaacc cttgcgggcc cgagccgccc gctcacgtcg tccgcgcgta caatcaacct
7141 gccggcgacg tcaggggcgt ttggggtaaa ggcgagcgca cctacgccga gcaggacttc
7201 cgcgtcggcg gcacgcgctg gcaccgactg ctgcgcatgc cagtgcgcgg cctcgacggc
7261 gacagcgccc cgcttccccc ccacaccacc gagcgcattg agacccgctc ggcgcgccat
7321 ccttggcgca tccgcttcgg tgccccccag gccttccttg ccgggctctt gctcgccacg
7381 gtcgccgttg gcaccgcgcg cgccgggctc cagccccgcg ctgatatggc ggcacctcct
7441 acgctgccgc agcccccctg tgcgcacggg cagcattacg gccaccacca ccatcagctg
7501 ccgttcctcg ggcacgacgg ccatcatggc ggcaccttgc gcgtcggcca gcattaccga
7561 aacgccagcg acgtgctgcc cggccactgg ctccaaggcg gctggggttg ctacaacctg
7621 agcgactggc accagggcac tcatgtctgt cataccaagc acatggactt ctggtgtgtg
7681 gagcacgacc gaccgccgcc cgcgaccccg acgcctctca ccaccgcggc gaactccacg
7741 accgccgcca cccccgccac tgcgccggcc ccctgccacg ccggcctcaa tgacagctgc
7801 ggcggcttct tgtctgggtg cgggccgatg cgcctgcgcc acggcgctga cacccggtgc
7861 ggtcggttga tctgcgggct gtccaccacc gcccagtacc cgcctacccg gtttggctgc
7921 gctatgcggt ggggccttcc cccctgggaa ctggtcgtcc ttaccgcccg ccccgaagac
7981 ggctggactt gccgcggcgt gcccgcccat ccaggcgccc gctgccccga actggtgagc
8041 cccatgggac gcgcgacttg ctccccagcc tcggccctct ggctcgccac agcgaacgcg
8101 ctgtctcttg atcacgccct cgcggccttc gtcctgctgg tcccgtgggt cctgatattt
8161 atggtgtgcc gccgcgcctg tcgccgccgc ggcgccgccg ccgccctcac cgcggtcgtc
8221 ctgcaggggt acaacccccc cgcctatggc gaggaggctt tcacctacct ctgcactgca
8281 ccggggtgcg ccactcaagc acctgtcccc gtgcgcctcg ctggcgtccg ttttgagtcc
8341 aagattgtgg acggcggctg ctttgcccca tgggacctcg aggccactgg agcctgcatt
8401 tgcgagatcc ccactgatgt ctcgtgcgag ggcttggggg cctgggtacc cgcagcccct
8461 tgcgcgcgca tctggaatgg cacacagcgc gcgtgcacct tctgggctgt caacgcctac
8521 tcctctggcg ggtacgcgca gctggcctct tacttcaacc ctggcggcag ctactacaag
8581 cagtaccacc ctaccgcgtg cgaggttgaa cctgccttcg gacacagcga cgcggcctgc
8641 tggggcttcc ccaccgacac cgtgatgagc gtgttcgccc ttgctagcta cgtccagcac
8701 cctcacaaga ccgtccgggt caagttccat acagagacca ggaccgtctg gcaactctcc
8761 gttgccggcg tgtcgtgcaa cgtcaccact gaacacccgt tctgcaacac gccgcacgga
8821 caactcgagg tccaggtccc gcccgacccc ggggacctgg ttgagtacat tatgaattac
8881 accggcaatc agcagtcccg gtggggcctc gggagcccga attgccacgg ccccgattgg
8941 gcctccccgg tttgccaacg ccattcccct gactgctcgc ggcttgtggg ggccacgcca
9001 gagcgccccc ggctgcgcct ggtcgacgcc gacgaccccc tgctgcgcac tgcccctgga
9061 cccggcgagg tgtgggtcac gcctgtcata ggctctcagg cgcgcaagtg cggactccac
9121 atacgcgctg gaccgtacgg ccatgctacc gtcgaaatgc ccgagtggat ccacgcccac
9181 accaccagcg acccctggca tccaccgggc cccttggggc tgaagttcaa gacagttcgc
9241 ccggtggccc tgccacgcac gttagcgcca ccccgcaatg tgcgtgtgac cgggtgctac
9301 cagtgcggta cccccgcgct ggtggaaggc cttgcccccg ggggaggcaa ttgccatctc
9361 accgtcaatg gcgaggacct cggcgccgtc ccccctggga agttcgtcac cgccgccctc
9421 ctcaacaccc ccccgcccta ccaagtcagc tgcgggggcg agagcgatcg cgcgaccgcg
9481 cgggtcatcg accccgccgc gcaatcgttt accggcgtgg tgtatggcac acacaccact
9541 gctgtgtcgg agacccggca gacctgggcg gagtgggctg ctgcccattg gtggcagctc
9601 actctgggcg ccatttgcgc cctcccactc gctggcttac tcgcttgctg tgccaaatgc
9661 ttgtactact tgcgcggcgc tatagcgcct cgctagtggg cccccgcgcg aaacccgcac
9721 taggccacta gatccccgca cctgttgctg tatag
References
- ↑ <pubmed>2353453</pubmed>
External Links
External Links Notice - The dynamic nature of the internet may mean that some of these listed links may no longer function. If the link no longer works search the web with the link text or name. Links to any external commercial sites are provided for information purposes only and should never be considered an endorsement. UNSW Embryology is provided as an educational resource with no clinical information or commercial affiliation.
Glossary Links
- Glossary: A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Numbers | Symbols | Term Link
Cite this page: Hill, M.A. (2024, April 19) Embryology Molecular Development - Rubella Genome. Retrieved from https://embryology.med.unsw.edu.au/embryology/index.php/Molecular_Development_-_Rubella_Genome
- © Dr Mark Hill 2024, UNSW Embryology ISBN: 978 0 7334 2609 4 - UNSW CRICOS Provider Code No. 00098G